v4j
Voynich for Java (v4j) library
Project maintained by mzattera Hosted on GitHub Pages — Theme by mattgraham
Note 012 - Mind your Words
Last updated Apr. 14th, 2026.
This note refers to release v.15.0.0 of v4j; links to classes and files refer to this release; files might have been changed, deleted or moved in the current master branch. In addition, some of this note content might have become obsolete in more recent versions of the library.
Working notes are not providing detailed description of algorithms and classes used; for this, please refer to the library code and JavaDoc.
Unless differently stated, this note uses the Slot alphabet.
Please refer to the home page for a set of definitions that might be relevant for this working note.
Abstract
In previous note 10 and 11, we saw how words behave differently at different position of the text; below a quick summary, please refer to original notes for details.
First line of paragraphs:
- Tokens in first line of each paragraph tend to be longer than other tokens, on average.
- Gallows (except for ‘k’ and ‘K’) tend to appear more frequently in first line of paragraphs, preferably in the first token of the line.
- There is also a preference for ‘S’ to appear in first line of paragraphs.
- Some “endings” (e.g. ‘E’, ‘B’, and ‘n’) avoids the first line of paragraphs.
First token in a line:
- The first token of a line is longer than average.
- Some characters, like ‘t’, ‘p’, ‘s’, ‘y’, and ‘d’ are over-represented at line start.
- Others characters, like ‘k’, ‘C’, ‘S’, ‘a’, and ‘r’ are under-represented.
Second token in a line:
- The second token of a line is shorter than average.
Last token in a line:
- ‘m’ is over represented, conversely, ‘l’ and ‘r’ are under-represented.
- For some clusters, ‘d’, ‘o’, ‘n’, and ‘y’ shows a significant deviation in their distribution.
In this note, I want to explore the hypothesis that there must be some word types that appear only in those positions of the text, which are responsible for the above patterns.
Methodology
For this note, the majority version of the Voynich was used; only the text in running paragraphs (IVTFF locus type = P0 or P1) is considered and tokens containing unreadable characters were ignored.
In the first test, I divided tokens in buckets, one per position in the line, so all tokens appearing at the beginning of a line are in the first bucket, those appearing in second position in a line go into the second bucket, and so on.
I then calculate, for each bucket, the percentage of word types that appear significantly more often in a bucket, compared to the totality of other buckets.
The experiment has been conducted separately for each cluster in both directions (from beginning and end of line){1}, results are shown below{2}. For comparison, the experiment was also executed on a scrambled version of the text where tokens where shuffled at random.
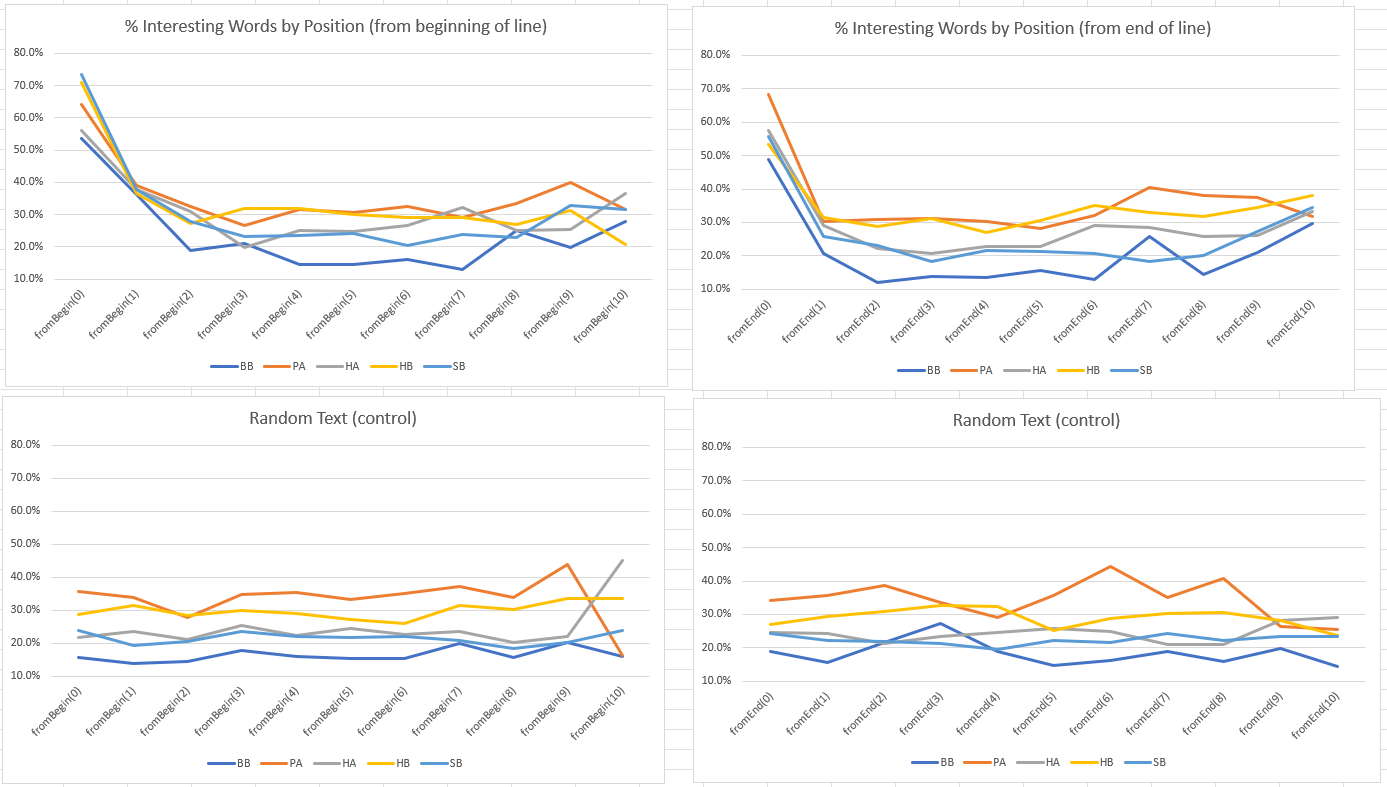
Clearly there are word types that prefer to appear only at first position or at end of line. Whether an unusual percentage of word types tend to appear more frequently in second position of a line is more dubious, but it also seems to be the case.
A similar experiment has been conducted by bucketing tokens based on which line in a paragraph they appear; below the results. The spike at the end in PA is probably due to the fact this cluster contains paragraphs with few lines, so less words are in lines after the fifth, introducing volatility.
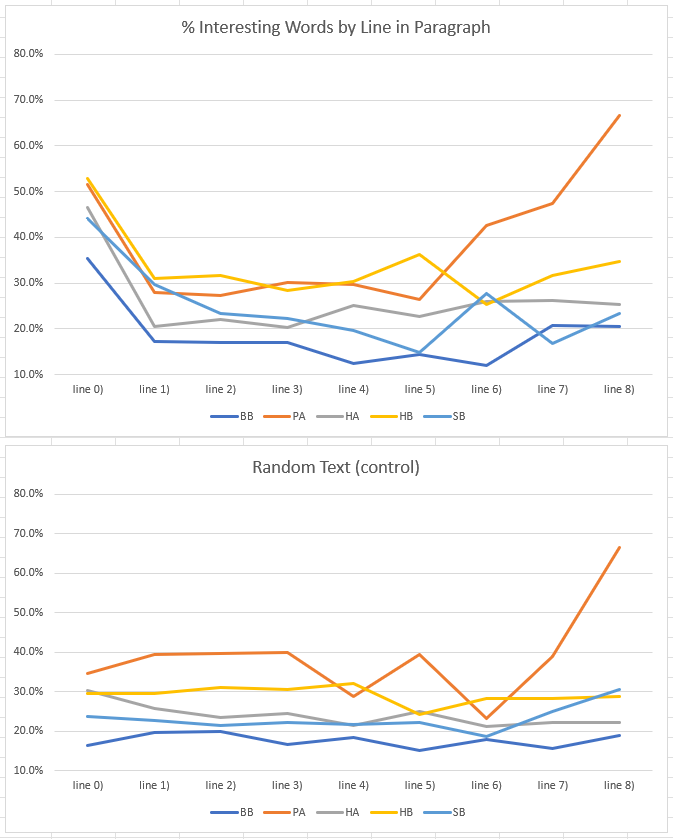
This also confirms that some words prefer to appear at beginning of line.
Conclusions
Our hypothesis seems to be confirmed: there are some word types that prefer to appear in first line of a paragraph, in first (and second?) or last position in a line.
These special words might be responsible for the behaviors we see in the text that are summarized at the beginning of this note.
We can define a population of “interesting words” as those appearing preferably in a given position in the text:
-
First line of paragraphs (in blue in the below illustration)
-
First token in a line (in green in the below illustration)
-
Second token in a line (in purple in the below illustration)
-
Last token in a line (in red in the below illustration)
and contrast this population with the “standard population”, defined as the set of words that do not appear in any of the above positions (circled in yellow in the below illustration).

Notes
{1} Class InterestingWords was used for this purpose.
{2} The file Interesting Words.xlsx in this folder contains
detailed results of the analysis, including diagrams.
Copyright Massimiliano Zattera.

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.