v4j
Voynich for Java (v4j) library
Project maintained by mzattera Hosted on GitHub Pages — Theme by mattgraham
Note 011 - On Length of Tokens
Last updated Dec. 29th, 2024.
This note refers to release v.14.0.0 of v4j; links to classes and files refer to this release; files might have been changed, deleted or moved in the current master branch. In addition, some of this note content might have become obsolete in more recent versions of the library.
Working notes are not providing detailed description of algorithms and classes used; for this, please refer to the library code and JavaDoc.
Please refer to the home page for a set of definitions that might be relevant for this working note.
Abstract
In VOGT (2012) there is an interesting analysis of tokens length across the Voynich. In this note I am trying to replicate the results:
- By using the Slot alphabet.
- Conducting a separate analysis for each cluster.
Methodology
For this note, the majority version of the Voynich was used; only the text in running paragraphs (IVTFF locus type = P0 or P1) is considered and tokens containing unreadable characters were ignored.
The average length of tokens is then calculated{1}:
- Considering tokens in same position in the line (e.g. first, second, third token in a line, etc.).
- Same but counting backwards (last token, second last, etc.).
- Considering tokens in same line of a paragraph, starting from top.
- Same but from bottom.
In addition, the same process is repeated for a text where the Voynich tokens were randomly shuffled, as a test. The results are shown below{2}:
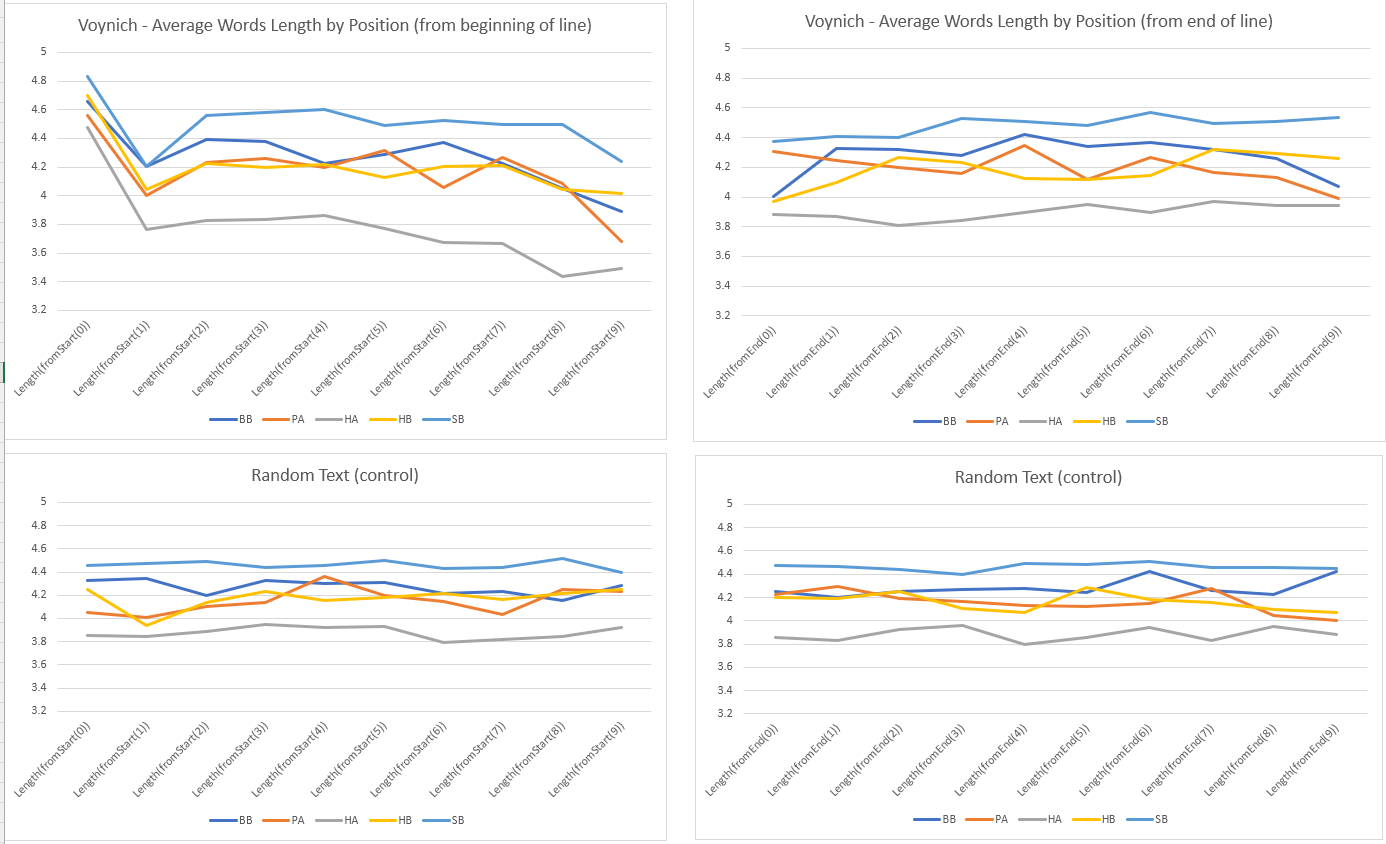
Average length of tokens by their position along the line:
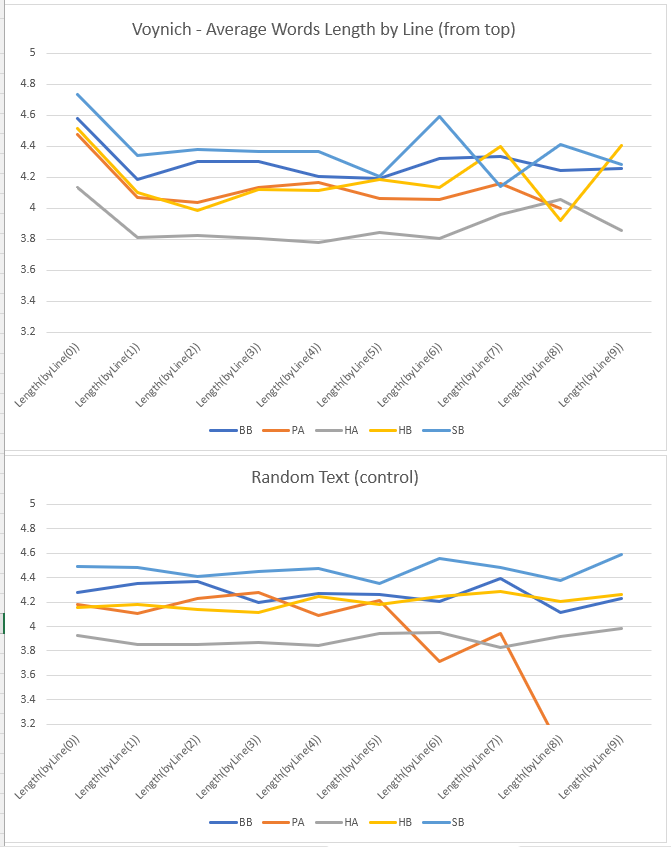
Average length of tokens by line:
Considerations and Comparison with Previous Works
Vogt makes three observations in his article:
- The first token of a line is longer than average.
- The second token is shorter.
-
Over the course of the line, the average token length drops.
This last effect is carefully analyzed and “explained away” as “the result of text composition along lines, namely that short words will result in lines with more words” and hence longer lines will have necessarily shorter words (notice shorter lines will not show in the graph, from a certain point on).
My analysis confirms all of the three observation, for each cluster separately.
For point 1., for which Vogt has no explanation, I suggest, as seen in Note 10 and in BOWERN (2020), this might the effect of prefixes added to first word in a line.
For point 2., I also have no clue so far as why it happens.
In addition, I checked if a similar phenomenon happens at the end of lines, but I cannot see any anomaly there. This should indirectly confirm Vogt’s analysis of point 3..
In this note, I also performed an analysis based on position of tokens in lines; this clearly shows tokens in first line are on average longer than those appearing in other lines. I think it is fair to attribute this to the presence of “Grove” words in the first line of paragraphs (see Note 10).
Conclusions
The behaviors indicated by Vogt are confirmed. In addition,
- Tokens at end of lines seem to behave “normally” in terms of length.
- Tokens in first line of each paragraph tend to be longer on average.
Notes
{1} Class WordLength was used for this purpose.
{2} The file Word Length.xlsx in this folder contains
detailed results of the analysis, including diagrams.
Copyright Massimiliano Zattera.

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.